
ChatGPTに難しい仕事を任せたら、かえって精度が下がった。
そんな実験結果があります。ハーバード大学とグローバルコンサルティングファームが、数百名のコンサルタントを対象に行った検証。簡単なタスクではGPT-4を使った群が量・速さ・質のすべてで勝ったのに、複数の情報源を読み解くような難しいケース問題では、AIを使った群のほうが正確さが下がったというのです(下げ幅の数字は本書で確認してほしい。なかなかの数字です)。
「AIが何でもやってくれる」は半分嘘です。本書はそこから話を始めます。アクセンチュアのデータ&AIグループによる一冊で、監修は保科学世さん。生成AI時代に、プログラミングができない普通のビジネスパーソンが「データを武器にする」ための実践ガイドです。
この本が刺さる人、刺さらない人
エンジニアやデータサイエンティストを目指す本ではありません。数式の証明やアルゴリズムの中身は意図的に省かれています。逆に「現場でデータをどう解釈し、どう人を動かすか」を知りたい文系ビジネスパーソンには、ぴったり刺さります。
ChatGPTに分析を任せたいが出てきた数字をどこまで信じていいかわからない人。会議で「データを見て判断しよう」と言われても、何をどう見ればいいか自信がない人。グラフは作れるのに「で、結論は?」と返されてしまう人。そういう、データの手前で立ち止まっている層に向けて書かれています。
著者がいちばん警戒しているのは、生成AIへの「妄信」です。GPTは平気で嘘をつく。本書の言葉だとハルシネーション。この世に存在しない事実をもっともらしく生成してしまう現象です。本書には「関東で一番高い山は?」と聞いてGPTが堂々と誤答する例が出てきますが、どの山をどう間違えたかは読んで笑ってほしいところ。
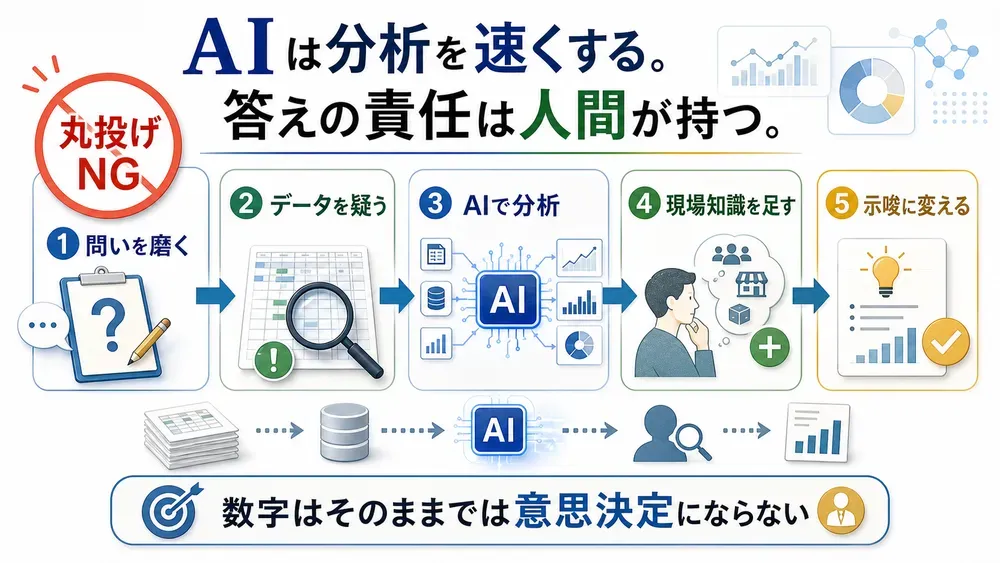
だから著者は、AIに全部を委ねることを勧めません。むしろ逆です。
使う側の知識・スキル・リテラシーなどの基礎力の底上げも重要なのです。
AIが高度になるほど、適切に指示を出し、出力の真偽を見極める人間の「基礎力」が効いてくる。これを著者は、勘・経験・度胸に頼る意思決定からの卒業として描きます。
分析は「何を解くか」でほぼ決まる
本書を貫く第一の主張は、データ分析の勝負は手を動かす前に決まっている、というものです。
多くの人がいきなりデータ収集から始めて失敗します。闇雲にデータを集め、グラフを量産し、何も決まらない。そうではなく、最初の段階でいかに筋のよい、ビジネスの本質をついた仮説を立てられるか。ここに分析全体の質がかかっている、と。
ここでMECEやロジックツリー、3Cといったフレームワークが登場します。私が良いと思ったのは、この枠組み作りこそ生成AIと相性がいいと言い切っている点です。「あなたは優秀なコンサルタントです。この課題を3Cで仮説立案してください」と壁打ちすれば、人間が見落とした切り口を補える。AIに枠組みのたたき台を出させ、人間はその妥当性の検証に時間を使う。丸投げでも放棄でもない、この役割分担の描き方が本書の肝です。
具体的なフレームワークの使い分けや課題の絞り込み方は、本書がいくつもの型を示しています。全部を覚える必要はなく、自分の仕事に効きそうなものを拾えばいい。
クラスタ分析という、データ分析の「入口」
統計・機械学習の手法は山ほどあります。でもビジネスでの目的は、過去や現在の傾向をつかむ「要約」と、未来を見立てる「予測」の2つに集約される、と本書は整理します。この交通整理だけでも、手法の海で溺れずに済みます。
代表として一つだけ挙げるなら、要約の側のクラスタ分析でしょう。似た特徴を持つデータを自動でグループ分けする手法で、たとえば百貨店の顧客を「子育てママ」「美食家」といったペルソナに束ねられる。そのうえでグループごとの売上を競合と比べれば、「競合に奪われている層にこの新商品を」という戦略が見えてくる。
ここで効いてくるのが、本書が繰り返す一言です。
同じ数字を眺めても、単独で数値を見ていた場合と、ビジネス的に適切な比較対象を用意して見比べた場合では、全く異なる結論になる。
自社の売上が前年比110%でも、市場全体が130%伸びていれば、実はシェアを落としている。正しい数字から、間違った結論はいくらでも出る。回帰分析や決定木、クロス集計の落とし穴、ChatGPTのData Analystでコードなしに分析する手順など、手を動かす側の話は本書がていねいに案内してくれます。
バイアスの章で、背筋が伸びる
本書でいちばんゾクッとするのが、データが人を欺く事例を並べた章です。
過去の逮捕データに引きずられて差別的な予測を生む犯罪予測システム。チョコレート消費量とノーベル賞受賞者数の相関に飛びついて疑似相関にはまる話。なかでも私が忘れられないのは、第二次大戦中に戦闘機のどこを補強すべきかを巡る逸話です。常識なら被弾の多い場所を直したくなる。でも統計学者ワルドは、まったく逆の結論にたどり着く——その答えは本書で味わってほしい。一度読むと、データの見方が反転します。
これらが教えるのは、データは客観的な真実ではない、ということ。誰がどう集め、何と比べるかで結論は変わる。生存バイアスも確証バイアスも、賢い人ほどはまる。だからこそ、この章は実務で数字を扱う全員に効きます。
数字に「現場の知識」を掛けて、初めて意味になる
そして本書がもっとも強調するのが、データにドメイン知識(その業界・業務の専門知識)を掛け合わせることです。これこそビジネスでデータ分析をやる醍醐味だ、と著者は言い切ります。
象徴的なのが、自動車保険の解約分析。「中価格帯の保険の解約率が最も高い」という数字が出ても、それだけでは理由はわからない。現場のメンバーと議論して初めて、その裏にある顧客の行動パターンが見えてくる——そこからどんな施策が生まれ、流出をどう食い止めたのか。数字の裏にある「物語」を現場知識が解き明かす過程は、読んでいて気持ちがいい。詳しい顛末は本書で。
人を動かすには、丸まった統計値だけでは足りないとも著者は言います。
他者に説明する際には意識してローデータ、最小粒度のデータに立ち戻り、そこから直接示唆を読み取る工夫を忘れてはならない。
平均値より、具体的な一人の顧客像。生のペルソナを見せたほうが、現場は納得して動く。本書の後半では、モデルを作って終わりにしない運用の話や「責任あるAI」、そしてAIと人間の役割をどう分けるかという問いまで広がっていきます。
読み終えて残るのは、分析手法の一覧ではありません。AIが出した数字を、そのまま信じない姿勢。データを真実ではなく、誰かが切り取った断片として疑う目。そして、数字に現場の知識を掛け合わせて初めて意味が生まれるという感覚です。
明日ChatGPTに分析を頼むとき、出てきたグラフを鵜呑みにする前に、一度だけ「この数字は、何と比べた数字だろう」と問い直してみてほしい。その小さな疑いから、本書の効果は立ち上がってきます。
合わせて読みたい
『外資系データサイエンティストの知的生産術』山本康正 本書が説く「データドリブン型ビジネス人材」の日常的な思考と習慣を、50の実践に分けて具体化した一冊です。プログラミングなしでデータから価値を生む、その手前の頭の使い方を補強できます。
『結局、仮説で決まる。』柏木吉基 本書の第一の主張「分析は課題定義と仮説立案でほぼ決まる」を、より深く掘り下げた本です。データ分析を学んだのに成果が出ない人が、なぜ手戻りするのかを仮説の質から解き明かしてくれます。
『「原因と結果」の経済学』中室牧子・津川友介 本書のバイアスの章で出てくる「チョコレートとノーベル賞」の疑似相関を、相関と因果の違いとして体系的に学べる一冊です。AIが出した数字に騙されないための、もう一段深い検証眼が手に入ります。



